I've been trying to review and summarize Eliezer Yudkowksy's recent dialogues on AI safety. Previously in sequence: Yudkowsky Contra Ngo On Agents. Now we’re up to Yudkowsky contra Cotra on biological anchors, but before we get there we need to figure out what Cotra's talking about and what's going on.
The Open Philanthropy Project ("Open Phil") is a big effective altruist foundation interested in funding AI safety. It's got $20 billion, probably the majority of money in the field, so its decisions matter a lot and it’s very invested in getting things right. In 2020, it asked senior researcher Ajeya Cotra to producea report on when human-level AI would arrive.It says the resulting document is "informal" - but it’s 169 pages long and likely to affect millions of dollars in funding, which some might describe as making it kind of formal. The report finds a 10% chance of “transformative AI” by 2031, a 50% chance by 2052, and an almost 80% chance by 2100.
Eliezer rejects their methodology and expects AI earlier (he doesn’t offer many numbers, but here he gives Bryan Caplan 50-50 odds on 2030, albeit not totally seriously). He made the case in his own very long essay,Biology-Inspired AGI Timelines: The Trick That Never Works, sparking a bunch of arguments and counterarguments and even more long essays.
There's a small cottage industry of summarizing the report already, eg OpenPhil CEO Holden Karnofsky's article and Alignment Newsletter editor Rohin Shah's comment. I've drawn from both for my much-inferior attempt.
Part I: The Cotra Report
Ajeya Cotra is a senior research analyst at OpenPhil. She's assisted by her fiancee Paul Christiano (compsci PhD, OpenAI veteran, runs an AI alignment nonprofit) and to a lesser degree by other leading lights. Although not everyone involved has formal ML training, if you care a lot about whether efforts are “establishment” or “contrarian”, this one is probably more establishment.
The report asks when will we first get "transformative AI" (ie AI which produces a transition as impressive as the Industrial Revolution; probably this will require it to be about as smart as humans). Its methodology is:
1. Figure out how much inferential computation the human brain does.
2. Try to figure out how much training computation it would take, right now, to get a neural net that does the same amount of inferential computation. Get some mind-bogglingly large number.
3. Adjust for "algorithmic progress", ie maybe in the future neural nets will be better at using computational resources efficiently. Get some number which, realistically, is still mind-bogglingly large.
4. Probably if you wanted that mind-bogglingly large amount of computation, it would take some mind-bogglingly large amount of money. But computation is getting cheaper every year. Also, the economy is growing every year. Also, the share of the economy that goes to investments in AI companies is growing every year. So at some point, some AI company will actually be able to afford that mind-boggingly-large amount of money, deploy the mind-bogglingly large amount of computation, and train the AI that has the same inferential computation as the human brain.
5. Figure out what year that is.
Does this encode too many questionable assumptions? For example, might AGI come from an ecosystem of interacting projects (eg how the Industrial Revolution came from an ecosystem of interacting technologies) such that nobody has to train an entire brain-sized AI in one run? Maybe - in fact, Ajeya thinks the Industrial Revolution scenario might be more likely than the single-run scenario. But she finds the single-run scenario as a useful upper bound (later she mentions other reasons to try it as a lower bound, and compromises by treating it as a central estimate) and still thinks it’s worth figuring out how long it will take.
So let’s go through the steps one by one:
How Much Computation Does The Human Brain Do?
Step one - figuring out how much computation the human brain does - is a daunting task. A successful solution would look like a number of FLOP/S (floating point operations per second), a basic unit of computation in digital computers. Luckily for Ajeya and for us, another OpenPhil analyst, Joe Carlsmith, finished a report on this a few months prior. It concluded the brain probably uses 10^13 - 10^17 FLOP/S. Why? Partly because this was the number given by most experts. But also, there are about 10^15 synapses in the brain, each one spikes about once per second, and a synaptic spike probably does about one FLOP of computation.
(I'm not sure if he's taking into account the recent research suggesting that computation sometimes happens within dendrites - see section 2.1.1.2.2 of his report for complications and why he feels okay ignoring them - but realistically there are lots of order-of-magnitude-sized gray areas here, and he gives a sufficiently broad range that as long as the unknown unknowns aren't all in the same direction it should be fine.)
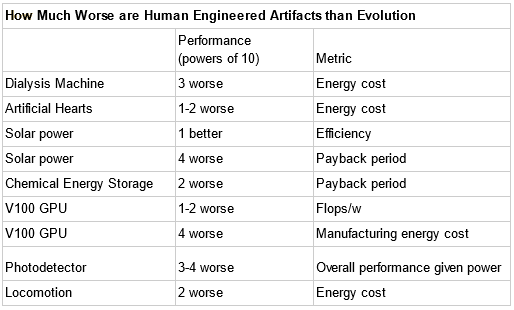
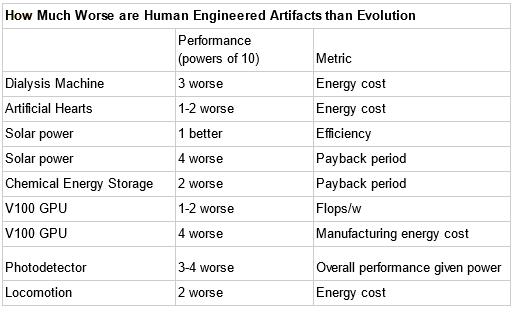
So a human-level AI would also need to do 10^15 floating point operations per second? Unclear. Computers can run on more or less efficient algorithms; neural nets might use their computation more or less effectively than the brain. You might think it would be more efficient, since human designers can do better than the blind chance of evolution. Or you might think it would be less efficient, since many biological processes are still far beyond human technology. Or you might do what OpenPhil did and just look at a bunch of examples of evolved vs. designed systems and see which are generally better:
Ajeya combines this with another metric where they see how existing AI compares to animals with apparently similar computational capacity; for example, she says that DeepMind’s Starcraft engine has about as much inferential compute as a honeybee and seems about equally subjectively impressive. I have no idea what this means. Impressive at what? Winning multiplayer online games? Stinging people? In any case, they decide to penalize AI by one order of magnitude compared to Nature, so a human-level AI would need to do 10^16 floating point operations per second.
How Much Compute Would It Take To Train A Model That Does 10^16 Floating Point Operations Per Second?
So an AI could potentially equal the human brain with 10^16 FLOP/S.
So why don’t we have AI yet? Why don’t we have ten AIs?
In the modern paradigm of machine learning, it takes very big computers to train relatively small end-product AIs. If you tried to train GPT-3 on the same kind of medium-sized computers you run it on, it would take between tens and hundreds of years. Instead, you train GPT-3 on giant supercomputers like the ones above, get results in a few months, then run it on medium-sized computers, maybe ~10x better than the average desktop.
But our hypothetical future human-level AI is 10^16 FLOP/S in inference mode. It needs to run on a giant supercomputer like the one in the picture. Nothing we have now could even begin to train it.
There’s no direct and obvious way to convert inference requirements to training requirements. Ajeya tries assuming that each parameter will contribute about 10 FLOPs, which would mean the model would have about 10^15 parameters (GPT-3 has about 10^11 parameters). Finally, she uses some empirical scaling laws derived from looking at past machine learning projects to estimate that training 10^15 parameters would require H*10^30 FLOPs, where H represents the model’s “horizon”.
If I understand this correctly, “horizon” is a reinforcement learning concept: how long does it take to learn how much reward you got for something? If you’re playing a slot machine, the answer is one second. If you’re starting a company, the answer might be ten years. So what horizon do you need for human level AI? Who knows? It probably depends on what human-level task you want the AI to do, plus how well an AI can learn to do that task from things less complex than the entire task. If writing a good book is mostly about learning to write good sentence and then stringing them together, a book-writing AI can get away with a short horizon. If nothing short of writing an entire book and then evaluating it to see whether it is good or bad can possibly teach you book-writing, the AI will need a long time horizon. Ajeya doesn’t claim to have a great answer for this, and considers three models: horizons of a few minutes, a few hours, and a few years. Each step up adds another three orders of magnitude, so she ends up with three estimates of 10^30, 10^33, and 10^36 FLOPs.
(for reference, the lowest training estimate - 10^30 - would take the supercomputer pictured above 300,000 years to complete; the highest, 300 billion.)
Or What If We Ignore All Of That And Do Something Else?
This is piling a lot of assumptions atop each other, so Ajeya tries three other methods of figuring out how hard this training task is.
Humans seem to be human-level AIs. How much training do we need? You can analogize our childhood to an AI’s training period. We receive a stream of sense-data. We start out flailing kind of randomly. Some of what we do gets rewarded. Some of what we do gets punished. Eventually our behavior becomes more sophisticated. We subject our new behavior to reward or punishment, fine-tune it further.
Rent asks us: how do you measure the life of a woman or man? It answers:“in daylights, in sunsets, in midnights, in cups of coffee; in inches, in miles, in laughter, in strife.” But you can also measure in floating point operations, in which case the answer is about 10^24. This is actually trivial: multiply the 10^15 FLOP/S of the human brain by the ~10^9 seconds of childhood and adolescence. This new estimate of 10^24 is much lower than our neural net estimate of 10^30 - 10^36 above. In fact, it’s only a hair above the amount it took to train GPT-3! If human-level AI was this easy, we should have hit it by accident sometime in the process of making a GPT-4 prototype. Since OpenAI hasn’t mentioned this, probably it’s harder than this and we’re missing something.
Probably we’re missing that humans aren’t blank slates. We don’t start at zero and then only use our childhood to train us further. The very structure of our brain encodes certain assumptions about what kinds of data we should be looking out for and how we should use it. Our training data isn’t just what we observed during childhood, it’s everything that any of our ancestors observed during evolution. How many floating-point operations is the evolutionary process?
Ajeya estimates 10^41. I can’t believe I’m writing this. I can’t believe someone actually estimated the number of floating point operations involved in jellyfish rising out of the primordial ooze and eventually becoming fish and lizards and mammals and so on all the way to the Ascent of Man. Still, the idea is simple. You estimate how long animals with neurons have been around for (10^16 seconds), total number of animals at any given second (10^20) times average number of FLOPS per animal (10^5) and you can read more here but it comes out to 10^41 FLOs. I would not call this an exact estimate - for one thing, it assumes that all animals are nematodes, on the grounds that non-nematode animals are basically a rounding error in the grand scheme of things. But it does justify this bizarre assumption, and I don’t feel inclined to split hairs here - surely the total amount of computation performed by evolution is irrelevant except as an extreme upper bound? Surely the part where Australia got all those weird marsupials wasn’t strictly necessary for the human brain to have human-level intelligence?
One more weird human training data estimate attempt: what about the genome? If in some sense a bit of information in the genome is a “parameter”, how many parameters does that suggest humans have, and how does it affect training time? Ajeya calculates that the genome has about 7.5x10^8 parameters (compared to 10^15 parameters in our neural net calculation, and 10^11 for GPT-3). So we can…
Okay, I’ve got to admit, this doesn’t have quite the same “huh?!” factor as trying to calculate the number of FLOs in evolution, but it is in a lot of ways even crazier. The Japanese canopy plant has a genome fifty times larger than ours, which suggests that genome size doesn’t correspond very well to organism awesomeness. Also, most of the genome is coding for weird proteins that stabilize the shape of your kidney tubule or something, why should this matter for intelligence?
The Japanese canopy plant. I think it is very pretty, but probably low prettiness per megabyte of DNA.
I think Ajeya would answer that she’s debating orders of magnitude here, and each of these weird things costs only a few OOMs and probably they all even out. That still leaves the question of why she thinks this approach is interesting at all, to which she answers that:
The motivating intuition is that evolution performed a search over a space of small, compact genomes which coded for large brains rather than directly searching over the much larger space of all possible large brains, and human researchers may be able to compete with evolution on this axis.
So maybe instead of having to figure out how to generate a brain per se, you figure out how to generate some short(er) program that can output a brain? But this would be very different from how ML works now. Also, you need to give each short program the chance to unfold into a brain before you can evaluate it, which evolution has time for but we probably don’t.
Ajeya sort of mentions these problems and counters with an argument that maybe you could think of the genome as a reinforcement learner with a long horizon. I don’t quite follow this but it sounds like the sort of thing that almost might make sense. Anyway, when you apply the scaling laws to a 7.5*10^8 parameter genome and penalize it for a long horizon, you get about 10^33 FLOPs, which is weirdly similar to some of the other estimates.
So now we have six different training cost estimates. First, neural nets with short, medium, and long horizons, which are 10^30, 10^33, and 10^36 FLOPs, respectively. Next, the amount of training data in a human lifetime - 10^24 FLOs - and in all of evolutionary history - 10^41 FLOPs. And finally, this weird genome thing, which is 10^33 FLOPs.
An optimist might say “Well, our lowest estimate is 10^24 FLOPs, our highest is 10^41 FLOPs, those sound like kind of similar numbers, at least there’s no “5 FLOPs” or “10^9999 FLOPs” in there.
A pessimist might say “The difference between 10^24 and 10^41 is seventeen orders of magnitude, ie a factor of 100,000,000,000,000,000 times. This barely constrains our expectations at all!”
Before we decide who to trust, let’s remember that we’re still only at Step 2 of our eight step Methodology, and continue.
How Do We Adjust For Algorithmic Progress?
So today, in 2022 (or in 2020 when this was written, or whenever), assume it would take about 10^33 FLOs to train a human-level AI.
But technology constantly advances. Maybe we’ll discover ways to train AIs faster, or run AIs more efficiently, or something like that. How does that factor into our estimate?
Ajeya draws on Hernandez & Brown’s Measuring The Algorithmic Efficiency Of Neural Networks. They look at how many FLOPs it took to train various image recognition AIs to an equivalent level of performance between 2012 and 2019, and find that over those seven years it decreased by a factor of 44x, ie training efficiency doubles every sixteen months! Ajeya assumes a doubling time slightly longer than that, because it’s easier to make progress in simple well-understood fields like image recognition than in the novel task of human-level AI. She chooses a doubling time of “merely” 2 - 3 years.
If training efficiency doubles every 2-3 years, it would dectuple in about 10 years. So although it might take 10^33 FLOPs to train a human level AI today, in ten years or so it may take only 10^32, in twenty years 10^31, and so on.
When Will Anyone Have Enough Computational Resources To Train A Human-Level AI?
In 2020, AI researchers could buy computational resources at about $1 for 10^17 FLOPs. That means the 10^33 FLOPs you’d need to train a human-level AI would cost $10^16, ie ten quadrillion dollars. This is about twenty times more money than exists in the entire world.
But compute costs fall quickly. Some formulations of Moore’s Law suggest it halves every eighteen months. These no longer seem to hold exactly, but it does seem to be halving maybe once every 2.5 years. The exact number is kind of controversial: Ajeya admits it’s been more like once every 3-4 years lately, but she heard good things about some upcoming chips and predicted it might revert back to the longer-term faster trend (it’s been two years now, some new chips have come out, and this prediction is looking pretty good).
So as time goes on, algorithmic progress will cut the cost of training (in FLOPs), and hardware progress will also cut the cost of FLOPs (in dollars). So training will become gradually more affordable as time goes on. Once it reaches a cost somebody is willing to pay, they’ll buy human-level AI, and then that will be the year human-level AI happens.
What is the cost that somebody (company? government? billionaire?) is willing to pay for human-level AI?
The most expensive AI training in history was AlphaStar, a DeepMind project that spent over $1 million to train an AI to play StarCraft (in their defense, it won). But people have been pouring more and more money into AI lately:
Source here. This is about compute rather than cost, but most of the increase seen here has been companies willing to pay for more compute over time, rather than algorithmic or hardware progress.
The StarCraft AI was kind of a vanity project, or science for science’s sake, or whatever you want to call it. But AI is starting to become profitable, and human-level AI would be very profitable. Who knows how much companies will be willing to pay in the future?
Ajeya extrapolates the line on the graph forward to 2025 and gets $1 billion. This is starting to sound kind of absurd - the entire company OpenAI was founded with $1 billion in venture capital, it seems like a lot to expect them to spend more than $1 billion on a single training run. So Ajeya backs off from this after 2025 and predicts a “two year doubling time”. This is not much of a concession. It still means that in 2040 someone might be spending $100 billion to train one AI.
Is this at all plausible? At the height of the Manhattan Project, the US was investing about 0.5% of its GDP into the effort; a similar investment today would be worth $100 billion. And we’re about twice as rich as 2000, so 2040 might be twice as rich as we are. At that point, $100 billion for training an AI is within reach of Google and maybe a few individual billionaires (though it would still require most or all of their fortune).
Ajeya creates a complicated function to assess how much money people will be willing to pay on giant AI projects per year. This looks like an upward-sloping curve. The line representing the likely cost of training a human-level AI looks like a downward sloping curve. At some point, those two curves meet, representing when human-level AI will first be trained.
So When Will We Get Human-Level AI?
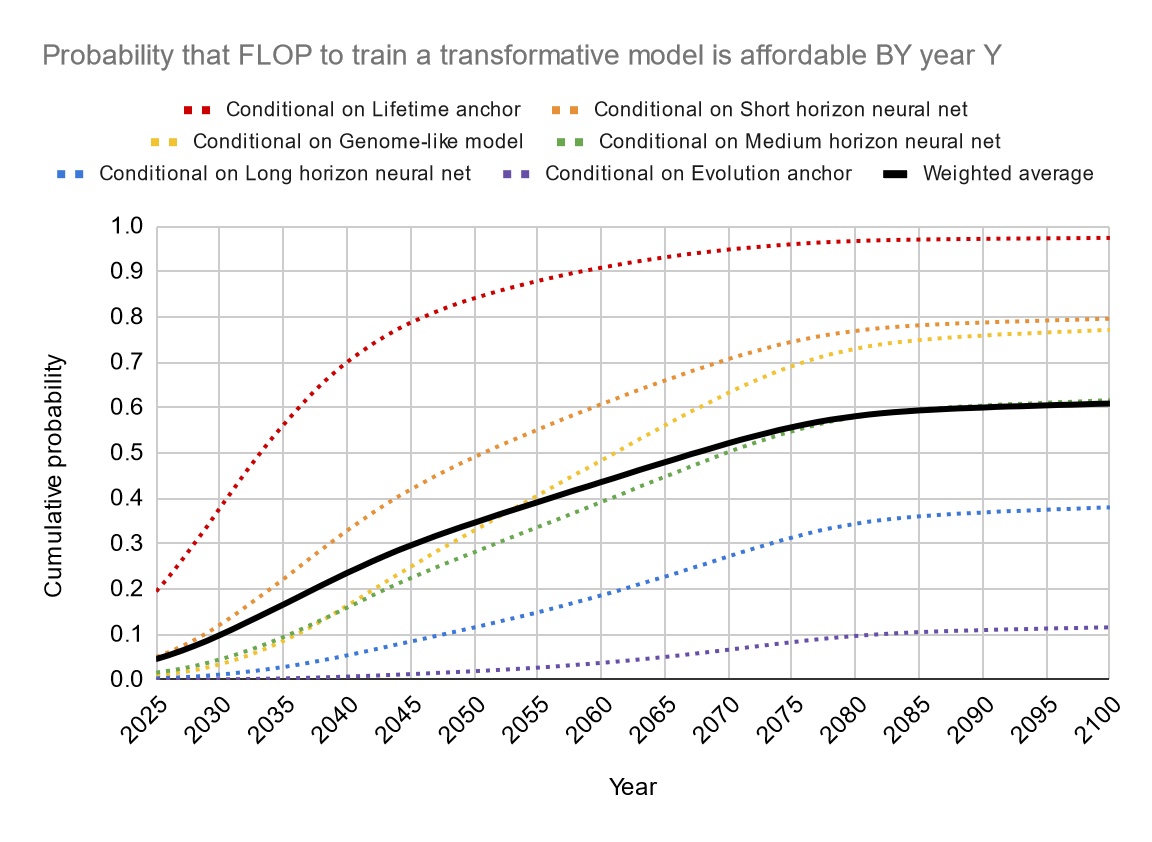
The report gives a long distribution of dates based on weights assigned to the six different models, each of which has really wide confidence intervals and options for adjusting the mean and variance based on your assumptions. But the median of all of that is 10% chance by 2031, 50% chance by 2052, and almost 80% chance by 2100.
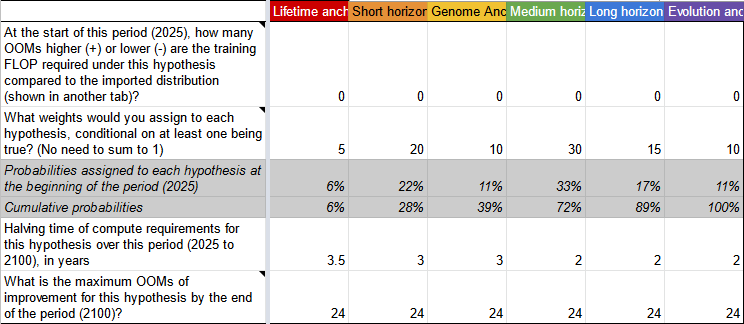
Ajeya takes her six models and decides to weigh them like so, based on how plausible she thinks each one is:
20% neural net, short horizon 30% neural net, medium horizon 15% neural net, long horizon 5% human lifetime as training data 10% evolutionary history as training data 10% genome as parameter number
She ends up with this:
How Sensitive Is This To Changes In Assumptions?
She very helpfully gives us a Colab notebook and Google spreadsheet to play around with. The notebook lets you change some of the more detailed parameters of the individual models, and the spreadsheet lets you change the big picture. I leave the notebook to people more dedicated to forecasting than I am, and will talk about the spreadsheet here.
If you’re following along at home, the default spreadsheet won’t reflect Ajeya’s findings until you fill in the table in the bottom left like so:
Great. Now that we’ve got that, let’s try changing some stuff. I like the human childhood training data argument (Lifetime Anchor) more than Ajeya does, and I like the size-of-the-genome argument less. I’m going to change the weights to 20-20-0-20-20-20. Also, Ajeya thinks that someone might be willing to spend 1% of national GDP on training AIs, but that sounds really high to me, so I’m going to down to 0.1%. Also, Ajeya’s estimate of 3% GDP growth sounds high for the sort of industrialized nations who might do AI research, I’m going to lower it to 2%.
Since I’m feeling mistrustful today, let’s use the Hernandez&Brown estimate for compute halving (1.5 years) in place of Ajeya’s ad hoc adjustments. And let’s use the current compute halving time (3.5 years) instead of Ajeya’s overly rosy version (2.5 years).
All these changes…
…don’t really do much. The median goes from 2052 to about 2065. Four of the models give results between 2030 and 2070. The last two, Neural Net With Long Horizon and Evolution, suggest probably no AI this century (although Neural Net With Long Horizon does think there’s a 40% chance by 2100). Ajeya doesn’t really like either of these models and they’re not heavily weighted in her main result.
Does The Truth Point To Itself?
Back up a second. Here’s something that makes me kind of nervous.
Most of Ajeya’s numbers are kind of made up, with several order-of-magnitude error bars and simplifying assumptions like “all animals are nematodes”. For a single parameter, we get estimates spanning seventeen different orders of magnitude: the upper bound is one hundred quadrillion times the lower bound.
And yet four of the six models, including two genuinely exotic ones, manage to get dates within twenty years of 2050.
And 2050 is also the date everyone else focuses on. Here’s the prediction-market-like site Metaculus:
Their distribution looks a lot like Ajeya’s, and even has the same median, 2052 (though forecasters could have read Ajeya’s report).
Katja Grace et al surveyed 352 AI experts, and they gave a median estimate of 2062 for an AI that could “outperform humans at all tasks” (though with many caveats and high sensitivity to question framing). This was before Ajeya’s report, so they definitely didn’t read it.
So lots of Ajeya’s different methods and lots of other people presumably using different methodologies or no methodology at all, all converge on this same idea of 2050 give or take a decade or two.
An optimist might say “The truth points to itself! There are 371 known proofs of the Pythagorean Theorem, and they all end up in the same place. That’s because no matter what methodology you use, if you use it well enough you get to the correct answer.”
A pessimist might be more suspicious; we’ll return to this part later.
FLOPS Alone Turn The Wheel Of History
One more question: what if this is all bullshit? What if it’s an utterly useless total garbage steaming pile of grade A crap?
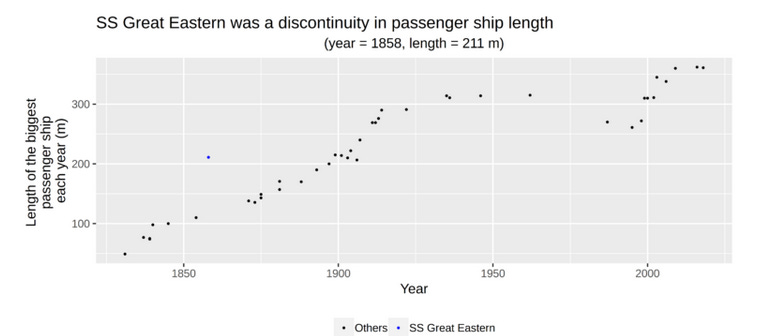
Imagine a scientist in Victorian Britain, speculating on when humankind might invent ships that travel through space. He finds a natural anchor: the moon travels through space! He can observe things about the moon: for example, it is 220 miles in diameter (give or take an order of magnitude). So when humankind invents ships that are 220 miles in diameter, they can travel through space!
Ships have certainly grown in size tremendously, from primitive kayaks to Roman triremes to Spanish galleons to the great ocean liners of the (Victorian) present.
The AI forecasting organization AI Impacts actually has a whole report on historical ship size trends to prove an unrelated point about technological progress, so I didn’t even have to make this graph up.
Suppose our Victorian scientist lived in 1858, right when the Great Eastern was launched. The trend line for ship size crossed 100m around 1843, and 200m in 1858, so doubling time is 15 years - but perhaps they notice this is going to be an outlier, so let’s round up a bit and say 18 years. The (one order of magnitude off estimate for the size of the) Moon is 350,000m, so you’d need ships to scale up by 350,000/200 = 1,750x before they’re as big as the Moon. That’s about 10.8 doublings, and a doubling time is 18 years, so we’ll get spaceships in . . . 2052 exactly.
(fudging numbers to land where you want is actually fun and easy)
SS Great Eastern, the extreme outlier large steamship from 1858. This has become sort of a mascot for quantitative technological progress forecasters.
What is this scientist’s error? The big one is thinking that spaceship progress depends on some easily-measured quantity (size) instead of on fundamental advances (eg figuring out how rockets work). You can make the same accusation against Ajeya et al: you can have all the FLOPs in the world, but if you don’t understand how to make a machine think, your AI will be, well, a flop.
Ajeya discusses this a bit on page 143 of her report. There is some sense in which FLOPs and knowing-what-you’re-doing trade of against each other. If you have literally no idea what you’re doing, you can sort of kind of re-run evolution until it comes up with something that looks good. If things are somehow even worse than that, you could always run AIXI, a hypothetical AI design guaranteed to get excellent results as long as you have infinite computation. You could run a Go engine by searching the entire branching tree structure of Go - you shouldn’t, and it would take a zillion times more compute than exists in the entire world, but you could. So in some sense what you’re doing, when you’re figuring out what you’re doing, is coming up with ways to do already-possible things more efficiently. But that’s just algorithmic progress, which Ajeya has already baked into her model.
(our Victorian scientist: “As a reductio ad absurdum, you could always stand the ship on its end, and then climb up it to reach space. We’re just trying to make ships that are more efficient than that.”)
Part II: Biology-Inspired AI Timelines: The Trick That Never Works
Ajeya’s report is a 169-page collection of equations, graphs, and modeling assumptions. Yudkowsky’s rebuttal is a fictional dialogue between himself, younger versions of himself, famous AI scientists, and other bit players. At one point, a character called “Humbali” shows up begging Yudkowsky to be more humble, and Yudkowsky defeats him with devastating counterarguments. Still, he did found the field, so I guess everyone has to listen to him.
He starts: in 1988, famous AI scientist Hans Moravec predicted human-level AI by 2010. He was using the same methodology as Ajeya: extrapolate how quickly processing power would grow (in FLOP/S), and see when it would match some estimate of the human brain. Moravec got the processing power almost exactly right (it hit his 2010 projection in 2008) and his human brain estimate pretty close (he says 10^13 FLOP/S, Ajeya says 10^15, this 2 OOM difference only delays things a few years), yet there was not human-level AI in 2010. What happened?
Ajeya's answer could be: Moravec didn't realize that, in the modern ML paradigm, any given size of program requires a much bigger program to train. Ajeya, who has a 35-year advantage on Moravec, estimates approximately the same power for the finished program (10^16 vs. 10^13 FLOP/S) but says that training the 10^16 FLOP/S program will require 10^33ish FLOPs.
Eliezer agrees as far as it goes, but says this points to a much deeper failure mode, which was that Moravec had no idea what he was doing. He was assuming processing power of human brain = processing power of computer necessary for AGI. Why?
The human brain consumes around 20 watts of power. Can we thereby conclude that an AGI should consume around 20 watts of power, and that, when technology advances to the point of being able to supply around 20 watts of power to computers, we'll get AGI? […]
You say that AIs consume energy in a very different way from brains? Well, they'll also consume computations in a very different way from brains! The only difference between these two cases is that you know something about how humans eat food and break it down in their stomachs and convert it into ATP that gets consumed by neurons to pump ions back out of dendrites and axons, while computer chips consume electricity whose flow gets interrupted by transistors to transmit information. Since you know anything whatsoever about how AGIs and humans consume energy, you can see that the consumption is so vastly different as to obviate all comparisons entirely.
You are ignorant of how the brain consumes computation, you are ignorant of how the first AGIs built would consume computation, but "an unknown key does not open an unknown lock" and these two ignorant distributions should not assert much internal correlation between them.
Cars don’t move by contracting their leg muscles and planes don’t fly by flapping their wings like birds. Telescopes do form images the same way as the lenses in our eyes, but differ by so many orders of magnitude in every important way that they defy comparison. Why should AI be different? You have to use some specific algorithm when you’re creating AI; why should we expect it to be anywhere near the same efficiency as the ones Nature uses in our brains?
The same is true for arguments from evolution, eg Ajeya’s Evolutionary Anchor, ie “it took evolution 10^43 FLOPs of computation to evolve the human brain so maybe that will be the training cost”. AI scientists sitting in labs trying to figure things out, and nematodes getting eaten by other nematodes, are such different methods for designing things that it’s crazy to use one as an estimate for the other.
Algorithmic Progress vs. Algorithmic Paradigm Shifts
This post is a dialogue, so (Eliezer’s hypothetical model of) OpenPhil gets a chance to respond. They object: this is why we put a term for algorithmic progress in our model. The model isn’t very sensitive to changes in that term. If you want you can set it to some kind of crazy high value and see what happens, but you can’t say we didn’t consider it.
OpenPhil: We did already consider that and try to take it into account: our model already includes a parameter for how algorithmic progress reduces hardware requirements. It's not easy to graph as exactly as Moore's Law, as you say, but our best-guess estimate is that compute costs halve every 2-3 years […]
Eliezer: The makers of AGI aren't going to be doing 10,000,000,000,000 rounds of gradient descent, on entire brain-sized 300,000,000,000,000-parameter models, algorithmically faster than today. They're going to get to AGI via some route that you don't know how to take, at least if it happens in 2040. If it happens in 2025, it may be via a route that some modern researchers do know how to take, but in this case, of course, your model was also wrong.
They're not going to be taking your default-imagined approach algorithmically faster, they're going to be taking an algorithmically different approach that eats computing power in a different way than you imagine it being consumed.
OpenPhil: Shouldn't that just be folded into our estimate of how the computation required to accomplish a fixed task decreases by half every 2-3 years due to better algorithms?
Eliezer: Backtesting this viewpoint on the previous history of computer science, it seems to me to assert that it should be possible to:
Train a pre-Transformer RNN/CNN-based model, not using any other techniques invented after 2017, to GPT-2 levels of performance, using only around 2x as much compute as GPT-2;
Play pro-level Go using 8-16 times as much computing power as AlphaGo, but only 2006 levels of technology.
For reference, recall that in 2006, Hinton and Salakhutdinov were just starting to publish that, by training multiple layers of Restricted Boltzmann machines and then unrolling them into a "deep" neural network, you could get an initialization for the network weights that would avoid the problem of vanishing and exploding gradients and activations. At least so long as you didn't try to stack too many layers, like a dozen layers or something ridiculous like that. This being the point that kicked off the entire deep-learning revolution.
Your model apparently suggests that we have gotten around 50 times more efficient at turning computation into intelligence since that time; so, we should be able to replicate any modern feat of deep learning performed in 2021, using techniques from before deep learning and around fifty times as much computing power.
OpenPhil: No, that's totally not what our viewpoint says when you backfit it to past reality. Our model does a great job of retrodicting past reality.
Eliezer: How so?
OpenPhil: <Eliezer cannot predict what they will say here.>
These are the two arguments Eliezer makes against OpenPhil that I find most persuasive. First, that you shouldn’t be using biological anchors at all. Second, that unpredictable paradigm shifts are more realistic than gradual algorithmic progress.
These mostly add uncertainty to OpenPhil’s model, but Eliezer ends his essay making a stronger argument: he thinks OpenPhil is directionally wrong, and AI will come earlier than they think.
Mostly this is the paradigm argument again. Five years from now, there could be a paradigm shift that makes AI much easier to build. It’s happened before; from GOFAI’s pre-programmed logical rules to Deep Blue’s tree searches to the sorts of Big Data methods that won the Netflix Prize to modern deep learning. Instead of just extrapolating deep learning scaling thirty years out, OpenPhil should be worried about the next big idea.
Hypothetical OpenPhil retorts that this is a double-edged sword. Maybe the deep learning paradigm can’t produce AGI, and we’ll have to wait decades or centuries for someone to have the right insight. Or maybe the new paradigm you need for AGI will take more compute than deep learning, in the same way deep learning takes more compute than whatever Moravec was imagining.
This is a pretty strong response, since it would have been true for every previous forecaster: remember, Moravec erred in thinking AI would come too soon, not too late. So although Eliezer is taking the cheap shot of saying OpenPhil’s estimate will be wrong just as everyone else’s was wrong before, he’s also giving himself the much harder case of arguing it might be wrong in the opposite direction as all its predecessors.
Eliezer takes this objection seriously, but feels like on balance probably new paradigms will speed up AI rather than slow it down. Here he grudgingly and with suitable embarrassment does try to make an object-level semi-biological-anchors-related argument: Moravec was wrong because he ignored the training phase. And the proper anchor for the training phase is somewhere between evolution and a human childhood, where evolution represents “blind chance eventually finding good things” and human childhood represents “an intelligent cognitive engine trying to squeeze as much data out of experience as possible”. And part of what he expects paradigm shifts to do is to move from more evolutionary processes to more childhood-like processes, and that’s a net gain in efficiency. So he still thinks OpenPhil’s methods are more likely to overestimate the amount of time until AGI rather than underestimate it.
What Moore’s Law Giveth, Platt’s Law Taketh Away
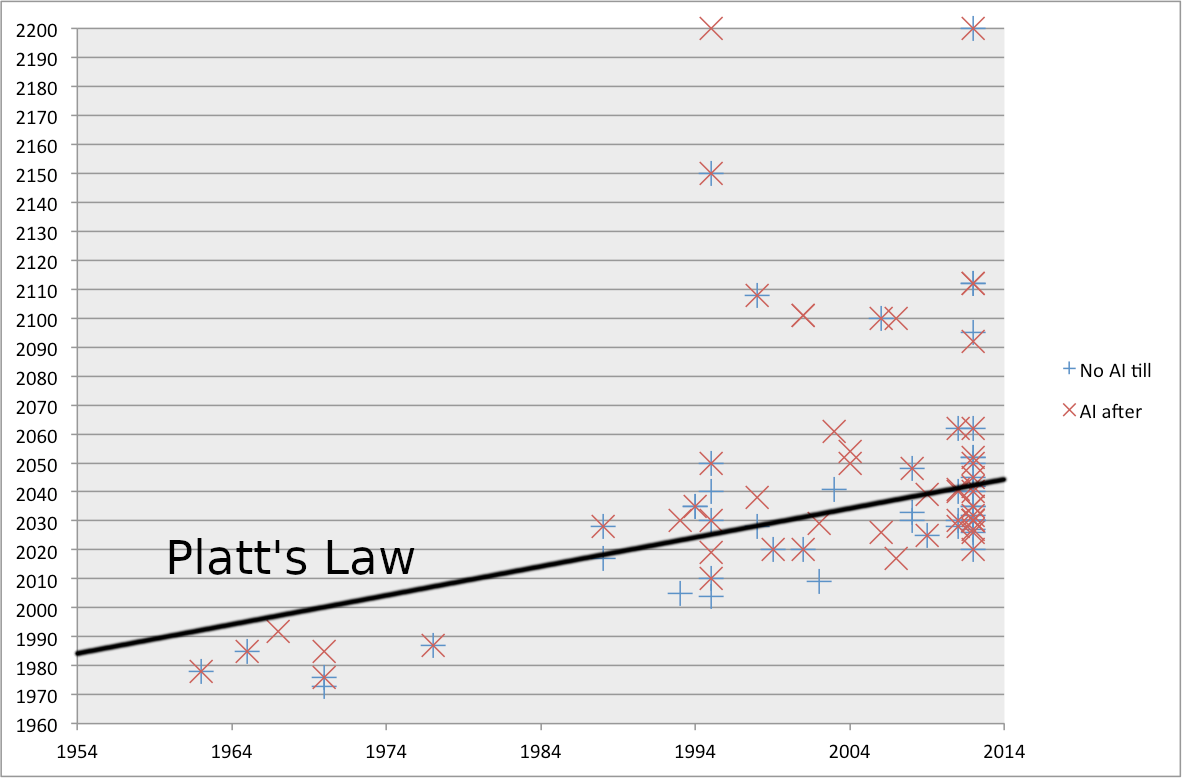
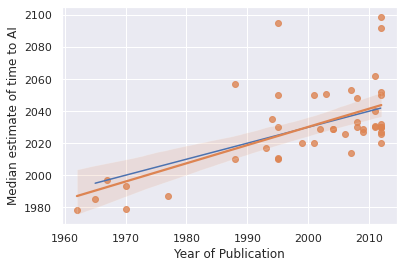
Eliezer’s other argument is kind of a low blow: he refers to Platt’s Law Of AI Forecasting: “any AI forecast will put strong AI thirty years out from when the forecast is made.”
This isn’t exact. Hans Moravec, writing in 1988, said 2010 - so 22 years. Ray Kurzweil, writing in 2001, said 2023 - another 22 years. Vernor Vinge, in a 1993 speech, said 2023, and that was exactly 30 years, but Vinge knew about Platt’s Law and might have been joking.
The point is: OpenPhil wrote a report in 2020 that predicted strong AI in 2052, isn’t that kind of suspicious?
I’d previously mentioned it as a plus that Ajeya got around the same year everyone else got. The forecasters on Metaculus. The experts surveyed in Grace et al. Lots of other smart experts with clever models. But what if all of these experts and models and analyses are just fudging the numbers for the same Platt’s-Law-related reasons?
Hypothetical OpenPhil is BTFO:
OpenPhil: That part about Charles Platt's generalization is interesting, but just because we unwittingly chose literally exactly the median that Platt predicted people would always choose in consistent error, that doesn't justify dismissing our work, right? We could have used a completely valid method of estimation which would have pointed to 2050 no matter which year it was tried in, and, by sheer coincidence, have first written that up in 2020. In fact, we try to show in the report that the same methodology, evaluated in earlier years, would also have pointed to around 2050 -
Eliezer: Look, people keep trying this. It's never worked. It's never going to work. 2 years before the end of the world, there'll be another published biologically inspired estimate showing that AGI is 30 years away and it will be exactly as informative then as it is now. I'd love to know the timelines too, but you're not going to get the answer you want until right before the end of the world, and maybe not even then unless you're paying very close attention. Timing this stuff is just plain hard.
Part III: Responses And Commentary
Response 1: Less Wrong Comments
Less Wrong is a site founded by Eliezer Yudkowsky for Eliezer Yudkowsky fans who wanted to discuss Eliezer Yudkowsky’s ideas. So, for whatever it’s worth - the comments on his essay were pretty negative.
Carl Shulman, an independent researcher with links to both OpenPhil and MIRI (Eliezer’s org), writes the top-voted comment. He works from a model where there is hardware progress, software progress downstream of hardware progress, and independent (ie unrelated to algorithms) software progress, and where the first two make up most progress on the margin. Researchers generally develop new paradigms once they have enough compute available to tinker with them.
Progress in AI has largely been a function of increasing compute, human software research efforts, and serial time/steps. Throwing more compute at researchers has improved performance both directly and indirectly (e.g. by enabling more experiments, refining evaluation functions in chess, training neural networks, or making algorithms that work best with large compute more attractive).
Historically compute has grown by many orders of magnitude, while human labor applied to AI and supporting software by only a few. And on plausible decompositions of progress (allowing for adjustment of software to current hardware and vice versa), hardware growth accounts for more of the progress over time than human labor input growth.
So if you're going to use an AI production function for tech forecasting based on inputs (which do relatively OK by the standards tech forecasting), it's best to use all of compute, labor, and time, but it makes sense for compute to have pride of place and take in more modeling effort and attention, since it's the biggest source of change (particularly when including software gains downstream of hardware technology and expenditures). […]
A perfectly correlated time series of compute and labor would not let us say which had the larger marginal contribution, but we have resources to get at that, which I was referring to with 'plausible decompositions.' This includes experiments with old and new software and hardware, like the chess ones Paul recently commissioned, and studies by AI Impacts, OpenAI, and Neil Thompson. There are AI scaling experiments, and observations of the results of shocks like the end of Dennard scaling, the availability of GPGPU computing, and Besiroglu's data on the relative predictive power of computer and labor in individual papers and subfields.
In different ways those tend to put hardware as driving more log improvement than software (with both contributing), particularly if we consider software innovations downstream of hardware changes.
Vanessa Kosoy makes the obvious objection, which echoes a comment of Eliezer’s in the dialogue above:
I'm confused how can this pass some obvious tests. For example, do you claim that alpha-beta pruning can match AlphaGo given some not-crazy advantage in compute? Do you claim that SVMs can do SOTA image classification with not-crazy advantage in compute (or with any amount of compute with the same training data)? Can Eliza-style chatbots compete with GPT3 however we scale them up?
For any given algorithm, e.g. SVMs, AlphaGo, alpha-beta pruning, convnets, etc., there is an "effective compute regime" where dumping more compute makes them better. If you go above this regime, you get steep diminishing marginal returns.
In the (relatively small) regimes of old algorithms, new algorithms and old algorithms perform similarly. E.g. with small amounts of compute, using AlphaGo instead of alpha-beta pruning doesn't get you that much better performance than like an OOM of compute (I have no idea if this is true, example is more because it conveys the general gist).
One of the main way that modern algorithms are better is that they have much large effective compute regimes. The other main way is enabling more effective conversion of compute to performance.
Therefore, one of primary impact of new algorithms is to enable performance to continue scaling with compute the same way it did when you had smaller amounts.
In this model, it makes sense to think of the "contribution" of new algorithms as the factor they enable more efficient conversion of compute to performance and count the increased performance because the new algorithms can absorb more compute as primarily hardware progress. I think the studies that Carl cites above are decent evidence that the multiplicative factor of compute -> performance conversion you get from new algorithms is smaller than the historical growth in compute, so it further makes sense to claim that most progress came from compute, even though the algorithms were what "unlocked" the compute.
Hmm... Interesting. So, this model says that algorithmic innovation is so fast that it is not much of a bottleneck: we always manage to find the best algorithm for given compute relatively quickly after this compute becomes available. Moreover, there is some smooth relation between compute and performance assuming the best algorithm for this level of compute. [EDIT: The latter part seems really suspicious though, why would this relation persist across very different algorithms?] Or at least this is true is "best algorithm" is interpreted to mean "best algorithm out of some wide class of algorithms s.t. we never or almost never managed to discover any algorithm outside of this class".
This can justify biological anchors as upper bounds[1]: if biology is operating using the best algorithm then we will match its performance when we reach the same level of compute, whereas if biology is operating using a suboptimal algorithm then we will match its performance earlier.
I definitely agree with your original-comment points about the general informativeness of hardware, and absolutely software is adapting to fit our current hardware. But this can all be true even if advances in software can make more than 20 orders of magnitude difference in what hardware is needed for AGI, and are much less predictable than advances in hardware rather than being adaptations in lockstep with it.
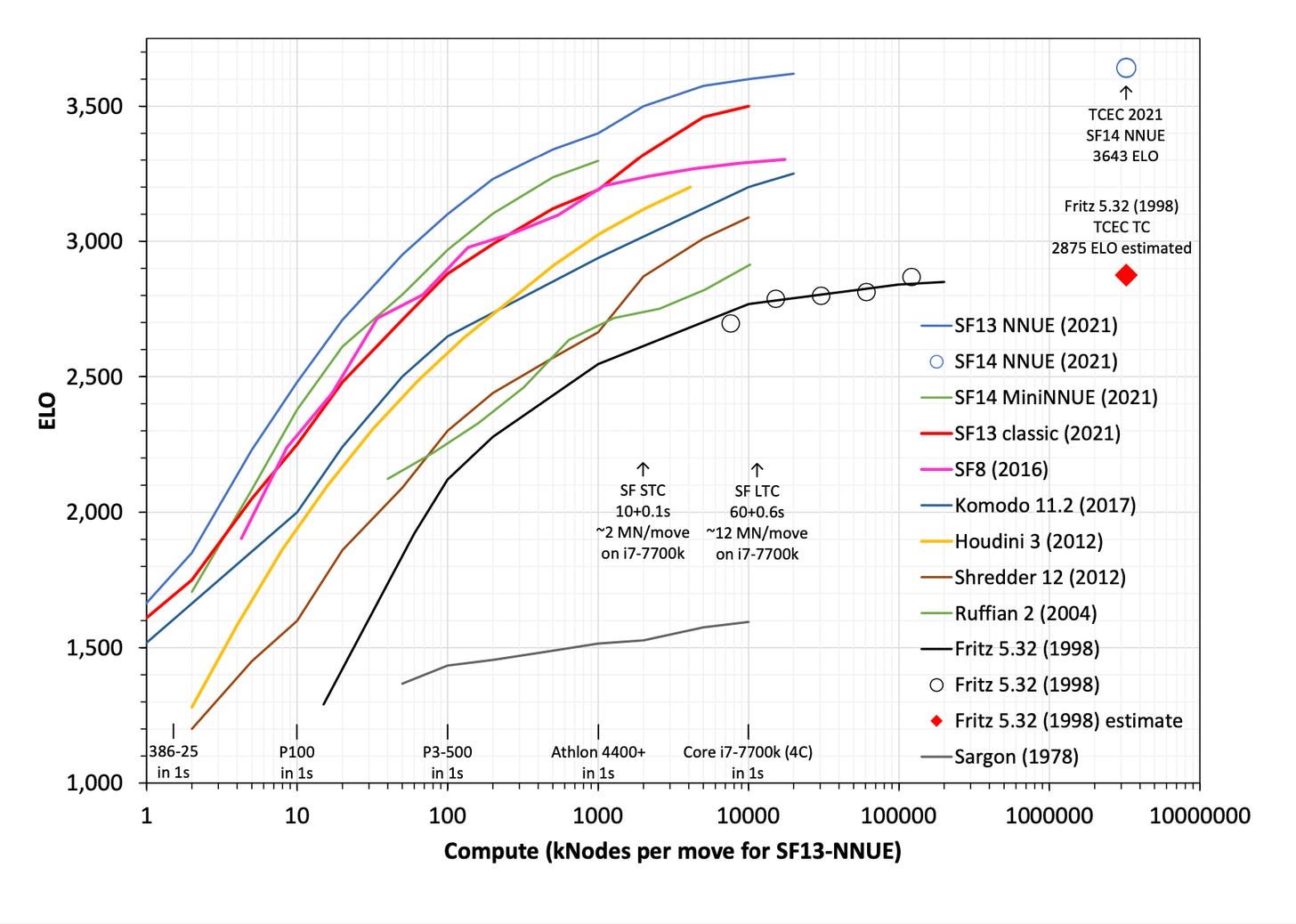
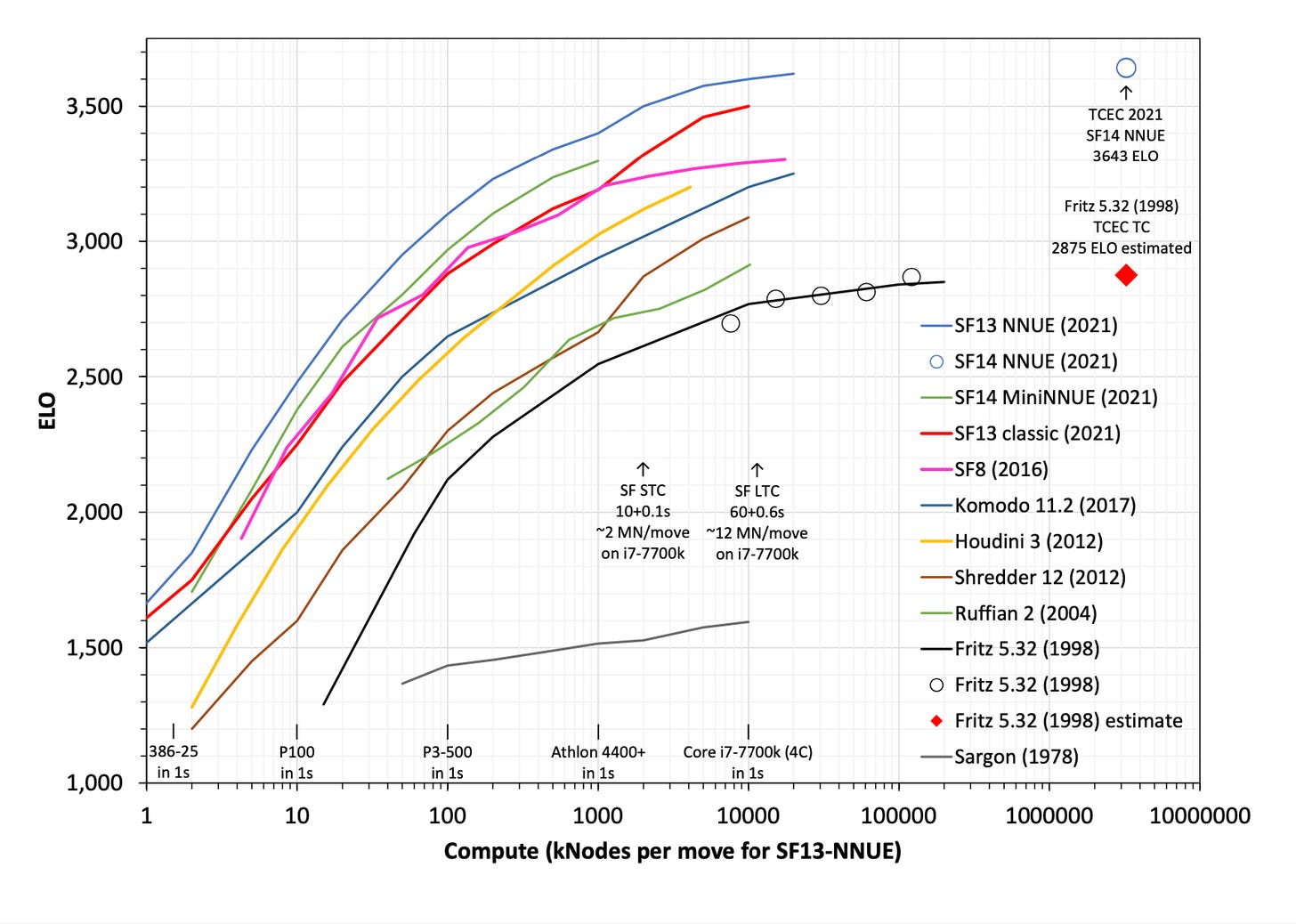
Here are the graphs from Hippke (he or I should publish summary at some point, sorry).
I wanted to compare Fritz (which won WCCC in 1995) to a modern engine to understand the effects of hardware and software performance. I think the time controls for that tournament are similar to SF STC I think. I wanted to compare to SF8 rather than one of the NNUE engines to isolate out the effect of compute at development time and just look at test-time compute.
So having modern algorithms would have let you win WCCC while spending about 50x less on compute than the winner. Having modern computer hardware would have let you win WCCC spending way more than 1000x less on compute than the winner. Measured this way software progress seems to be several times less important than hardware progress despite much faster scale-up of investment in software.
But instead of asking "how well does hardware/software progress help you get to 1995 performance?" you could ask "how well does hardware/software progress get you to 2015 performance?" and on that metric it looks like software progress is way more important because you basically just can't scale old algorithms up to modern performance.
The relevant measure varies depending on what you are asking. But from the perspective of takeoff speeds, it seems to me like one very salient takeaway is: if one chess project had literally come back in time with 20 years of chess progress, it would have allowed them to spend 50x less on compute than the leader.
Response 2: AI Impacts + Matthew Barnett
AI Impacts gathered and analyzed a dataset of who predicted AI when; Matthew Barnett helpfully drew in the line corresponding to Platt’s Law (everyone always predicts AI in thirty years).
Just eyeballing it, Platt’s Law looks pretty good. But Holden Karnofsky (see below) objects that our eyeballs are covertly removing outliers. Barnett agrees this is worth checking for and runs a formal OLS regression.
I agree this trendline doesn't look great for Platt's law, and backs up your observation by predicting that Bio Anchors should be more than 30 years out.
However, OLS is notoriously sensitive to outliers. If instead of using some more robust regression algorithm, we instead super arbitrarily eliminated all predictions after 2100, then we get this, which doesn't look absolutely horrible for the law. Note that the median forecast is 25 years out.
I’m split on what to think here. If we consider a weaker version of Platt’s Law, “the average date at which people forecast AGI moves forward at about one year per year”, this seems truish in the big picture where we compare 1960 to today, but not obviously true after 1980. If we consider a different weaker version, “on average estimates tend to be 30 years away”, that’s true-ish under Barnett’s revised model, but not inherently damning since Barnett’s assuming there will be some such number, it turns out to be 25, and Ajeya gave the somewhat different number of 32. Is that a big enough difference to exonerate her of “using” Platt’s Law? Is that even the right way to be thinking about this question?
Response 3: Real OpenPhil
The hypothetical OpenPhil in Eliezer’s mind having been utterly vanquished, the real-world OpenPhil is forced to step in. OpenPhil CEO Holden Karnofsky responds to Eliezer here.
There’s a lot of back and forth about whether the report includes enough caveats (answer: it sure does include a lot of caveats!) but I was most interested in the attacks on Eliezer’s two main points.
First, the point that biological anchors are fatally flawed from the start and measuring FLOP/S is no better than measuring power consumption in watts. Holden:
If the world were such that:
We had some reasonable framework for "power usage" that didn't include gratuitously wasted power, and measured the "power used meaningfully to do computations" in some important sense;
Power usage was just now coming within a few orders of magnitude of the human brain;
We were just now starting to see AIs have success with tasks like vision and speech recognition (tasks that seem likely to have been evolutionarily important, and that we haven't found ways to precisely describe GOFAI-style);
It also looked like AI was starting to have insect-like capabilities somewhere around the time it was consuming insect-level amounts of power;
And we didn't have some clear candidate for a better metric with similar properties (as I think we do in the case of computations, since the main thing I'd expect increased power usage to be useful for is increased computation);
...Then I would be interested in a Bio Anchors-style analysis of projected power usage. As noted above, I would be interested in this as a tool for analysis rather than as "the way to get my probability distribution." That's also how I'm interested in Bio Anchors (and how it presents itself).
Second, the argument that paradigm shifts might speed up AI:
I think it's a distinct possibility that we're going to see dramatically new approaches to AI development by the time transformative AI is developed.
On the other, I think quotes like this overstate the likelihood in the short-to-medium term.
Deep learning has been the dominant source of AI breakthroughs for nearly the last decade, and the broader "neural networks" paradigm - while it has come in and out of fashion - has broadly been one of the most-attended-to "contenders" throughout the history of AI research.
AI research prior to 2012 may have had more frequent "paradigm shifts," but this is probably related to the fact that it was seeing less progress.
With these two points in mind, it seems off to me to confidently expect a new paradigm to be dominant by 2040 (even conditional on AGI being developed), as the second quote above implies. As for the first quote, I think the implication there is less clear, but I read it as expecting AGI to involve software well over 100x as efficient as the human brain, and I wouldn't bet on that either (in real life, if AGI is developed in the coming decades - not based on what's possible in principle.)
Reponse 4: Me
Oh God, I have to write some kind of conclusion to this post, in some way that suggests I have an opinion, or that I’m at all qualified to assess this kind of research. Oh God oh God.
I find myself most influenced by two things. First, Paul’s table of how effectively Nature tends to outperform humans, which I’ll paste here again:
I find it hard to say how this influenced me. It would be great if Paul had found some sort of beautiful Moore’s-Law-esque rule for figuring out the Nature vs. humans advantage. But actually his estimates span five orders of magnitude. And they don’t even make sense as stable estimates - human solar power a few decades ago was several orders of magnitude worse than Nature’s, and a few decades from now it may be better.
Still, I think this table helps the whole thing feel less mystical. Usually Nature outperforms humans by some finite amount, usually a few orders of magnitude, on the dimension we care about. We can add it to the error bars on our model and move on.
The second thing that influences me a lot is Carl Shulman’s model of “once the compute is ready, the paradigm will appear”. Some other commenters visualize this as each paradigm having a certain amount of compute you can “feed” it before it stops scaling with compute effectively. This is a heck of a graph:
Given these two assumptions - that natural artifacts usually have efficiencies within a few OOM of artificial ones, and that compute drives progress pretty reliably - I am proud to be able to give Ajeya’s report the coveted honor of “I do not make an update of literally zero upon reading it”.
That still leaves the question of “how much of an update do I make?” Also “what are we even doing here?”
That is - suppose before we read Ajeya’s report, we started with some distribution over when we’d get AGI. For me, not being an expert in this area, this would be some combination of the Metaculus forecast and the Grace et al expert survey, slightly pushed various directions by the views of individual smart people I trust. Now Ajeya says maybe it’s more like some other distribution. I should end up with a distribution somewhere in between my prior and this new evidence. But where?
I . . . don’t actually care? I think Metaculus says 2040-something, Grace says 2060-something, and Ajeya says 2050-something, so this is basically just the average thing I already believed. Probably each of those distributions has some kind of complicated shape, but who actually manages to keep the shape of their probability distribution in their head while reasoning? Not me.
This report was insufficiently different from what I already believed for me to need to worry about updating from one to the other. The more interesting question, then, is whether I should update towards Eliezer’s slightly different distribution, which places more probability mass on earlier decades.
But Eliezer doesn’t say what his exact probability distribution is, and he does say he’s making a deliberate choice not to do this:
I consider naming particular years to be a cognitively harmful sort of activity; I have refrained from trying to translate my brain's native intuitions about this into probabilities, for fear that my verbalized probabilities will be stupider than my intuitions if I try to put weight on them. What feelings I do have, I worry may be unwise to voice; AGI timelines, in my own experience, are not great for one's mental health, and I worry that other people seem to have weaker immune systems than even my own. But I suppose I cannot but acknowledge that my outward behavior seems to reveal a distribution whose median seems to fall well before 2050.
So, should I update from my current distribution towards a black box with “EARLY” scrawled on it?
What would change if I did? I’d get scared? I’m already scared. I’d get even more scared? Seems bad.
Maybe I’d have different opinions on whether we should pursue long-term AI alignment research programs that will pay off after 30 years, vs. short-term AI alignment research programs that will pay off in 5? If you have either of those things, please email anyone whose name has been mentioned in this blog post, and they’ll arrange to have a 6-to-7-digit sum of money thrown at you immediately. It’s not like there’s some vast set of promising 30-year research programs and some other set of promising 5-year research programs that have to be triaged against each other. Maybe there’s some ability to redirect a little bit of talent and interest at the margin, in a way that makes it worth OpenPhil’s time to care. But should I care? Should you?
An astronomy professor says that the sun will explode in five billion years, and sees a student visibly freaking out. She asks the student what’s so scary about the sun exploding in five billion years. The student sighs with relief: “Oh, thank God! I thought you’d said five million years!”
And once again, you can imagine the opposite joke: A professor says the sun will explode in five minutes, sees a student visibly freaking out, and repeats her claim. The student, visibly relieved: “Oh, thank God! I thought you’d said five seconds.”
Here Ajeya is the professor saying the sun will explode in five minutes instead of five seconds. Compared to the alternative, it’s good news. But if it makes you feel complacent, then the joke’s on you.
Share this discussion
Biological Anchors: A Trick That Might Or Might Not Work







{kind=link}
Biological Anchors: A Trick That Might Or Might Not Work